

This is a series of blog posts that we at Sapling are composing on meaningful conversational insights into customer support conversations. For more, please subscribe below.
Knowledge workers—such as support agents and inside sales representatives—need onboarding and training so that they can best respond to customers. Even with the best training and learning management systems, however, agents will still often need to sift through the company knowledge base in order to determine the best response or next best action when dealing with customers. In this post, we discuss challenges and promising opportunities with systems for creating, managing, and distributing knowledge for customer-facing teams.
The Knowledge Lifecycle
Knowledge for agents undergoes a lifecycle:
- New topic: Something that hasn’t been encountered before. Long tail theory suggests that this can happen much more frequently than one would expect.
- Breadcrumbs: The company has a small set of conversation transcripts. At this point agents and managers can review these conversations and use them in new threads, but they are not yet part of the shared knowledge base.
- Accepted standard: There becomes a standard accepted set of responses and procedures. Common responses and procedures may be candidates for automation or self service.
- Automation: Automation is deployed, if possible — which for non-transactional conversations it may not be.
- Deprecation: An existing knowledge article or process becomes stale or deprecated. It’s then gradually removed from systems and replaced with new knowledge from Step 1.
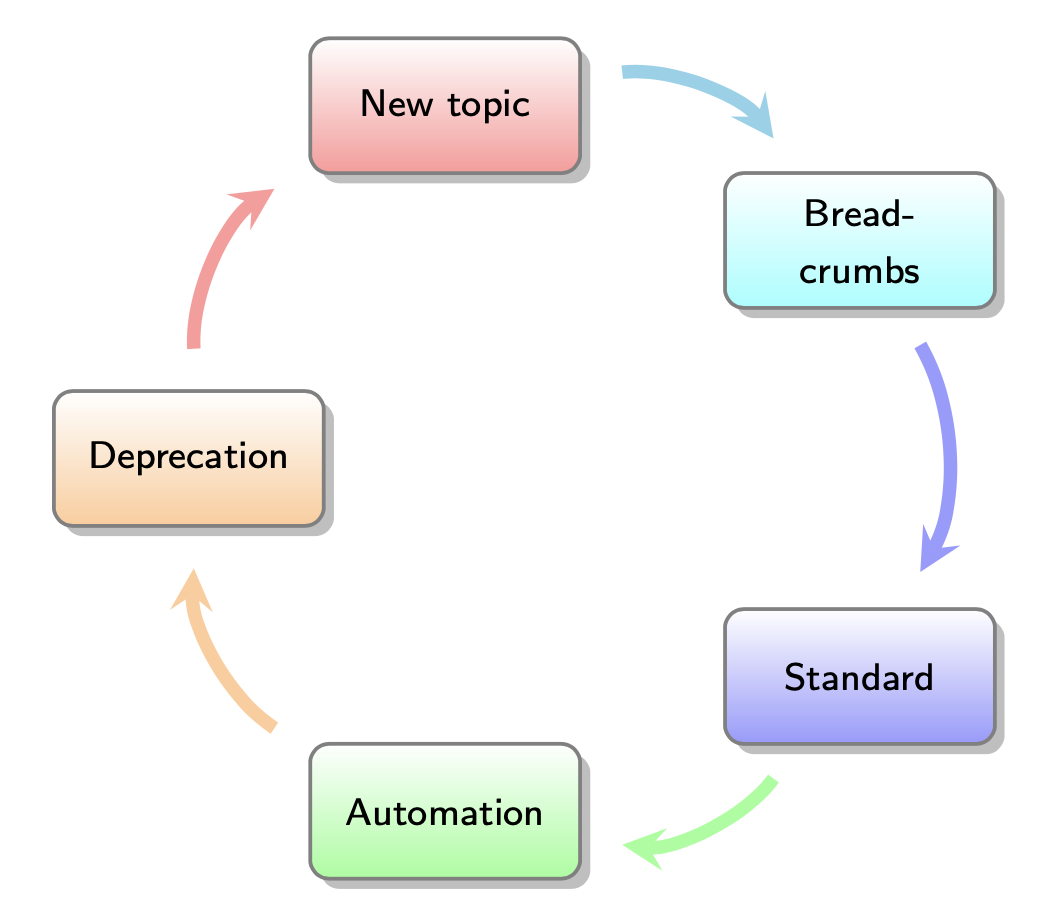
The knowledge lifecycle.
At each stage of the lifecycle, there exists different challenges.
Challenges
Kickstarting the knowledge base
More than likely, there are already pieces of knowledge scattered across the org in the CRM, Google Docs, spreadsheets, and a variety of other sources. The first step then is to transform, aggregate, and organize this information in a knowledge management system (KMS). This sink might be in the helpdesk software, such as Zendesk, or a more general note-taking system such as Notion.so or Coda.
While some drudgery during the process of aggregating and transforming the knowledge sources is unavoidable, a key consideration is the ease of accessing and sending the knowledge to new sinks after it has been collected. This might be in the form of technical integrations, common export formats, or an easily accessible search interface.
Surfacing gaps
… there are known knowns; there are things we know we know. We also know there are known unknowns; … But there are also unknown unknowns.
— Donald Rumsfeld
Related to processing inbound requests is identifying the knowledge gaps in the existing documentation or response bank.
Some topics are already well-documented and can be left alone for agents to use. Others are on the backlog of items to be addressed.
More interesting, though, are the so-called unknown unknowns—topics that could be added and that would help agents, but are not on the radar of the team. Especially for larger teams with siloed roles, it can take some time for such topics to bubble up, get implemented org-wide, and propagate to agents again.
A number of tools have been coming out to monitor conversations for calls — e.g. Gong.io for sales teams or Observe.ai for support teams. Such tools allow managers to quickly glean information that previously required infeasible amounts of manual review.
One tool we at Sapling.ai have developed for this is called Trends. Similar to word clouds, by using natural language processing techniques trends can identify anomalous topics for each day over the previous month or more. It makes it easy for managers to identify where additional documentation and knowledge base information should be created. Trends also clusters common topics based off of semantic similarity so that teams can glean coverage of different topics — and identify redundant information.

Example view of Trends.
A single, shared knowledge base
Much like with customer relationship management (CRM) software, the chosen knowledge base should be the source of truth for agents. Such consistent usage can be difficult to enforce, however, when it takes many clicks and keystrokes to retrieve the right information and transfer it to the active workspace. Integrations are one solution—for example integrations that automatically deliver notifications to Slack.
At Sapling, our browser integrations come with Snippets, a feature that allows agents to search shared repository of knowledge snippets from any webpage. Besides fast search, snippets can also be inserted based on specified keystroke sequences. For documents and spreadsheets, Sapling can also scan for prompts and auto-populate with suggested responses.
Keeping knowledge up-to-date
Once knowledge reaches the end of its lifecycle, it should be edited or deleted entirely to avoid conflicting information. Especially if knowledge is dispersed across different systems, it can be difficult to ensure such stale information is handled.
Tools such as Guru make it easy for managers to regularly confirm if a piece of knowledge is up-to-date or needs revisions. But as a first step, aggregating information in a single system that is easily searchable makes knowledge management much easier.
Bridging the process automation chasm
In his seminal work, “Crossing the Chasm”, Geoffrey Moore points out that technology products often stumble upon a chasm when trying to make the transition from so-called early adopters to an early majority. This phenomenon is also illustrated in other forms such as the Gartner Hype Cycle.
Automating processes is difficult. Although knowledge work is primarily digital, it can also involve many inputs and moving pieces: multiple communication channels (email, chat, calls), multiple systems of record, multiple data formats, all of which need to interoperate with a single point of failure often breaking the entire process.
It’s easy to find analogies for automation of knowledge processes. Autonomous driving initiatives define levels of automation ranging from partial assistance (e.g. cruise control) to self-driving modes with driver supervision. Across manufacturing warehouses, robots and humans work side-by-side with humans often handling steps that have smaller items or require tactile maneuvering.
At Sapling.ai, we evaluated various chatbot solutions, but eventually arrived at Suggest. Suggest surfaces responses to agents based off of customer inquiries in the chat log. Agents can then simply click on the appropriate response—or ignore the suggested responses, if not relevant—to quickly provide information to the customer.
Towards a Solution
With these challenges, what software solution might help?
- A tool that integrates everywhere.
- A tool that is always on and able to assist when appropriate.
- A tool that helps surface new knowledge topics.
- A tool that is flexible enough for automations to consistently work.
We’d love to get your thoughts and discuss. Comment below or get in touch.
